
Natural Language Processing for MEDical TERMinologyProject funded by InterTalentum UAM, Marie Skłodowska-Curie COFUND, (2019-2021) at The Autonomous University of Madrid (Universidad Autónoma de Madrid) |
 |
Objectives
The NLPMedTerm project aims at providing the research community with resources for natural language processing (NLP) in the health domain for Spanish.
Work Package 1: an enriched lexicon of medical terms. It includes Concept Unique Identifiers (CUI) from the Unified Medical Language System© (UMLS©). → Deliverable 1 ![]()
Linguistic information of terms is provided, and the Part-of-Speech (PoS) category is currently being added. Compositional/derivational data of medical terms are provided, and the equivalence between synonym roots and affixes (e.g. cardio- / cardiac-).
Work Package 2: a corpus texts annotated with medical entities as a resource for experiments in Named Entity Recognition. The corpus is aimed at training machine-learning models incorporating state-of-the-art neural network approaches. → Deliverable 2 ![]()
In this Work Package, we have also created word embeddings from the medical domain → Deliverable 3 ![]()
Collaborators in Work Package 2:
- Dr. Adrián Capllonch Carrión, Complejo Asistencial Benito Menni, Ciempozuelos, Madrid, Spain
- Dra. Ana Valverde Mateos, Unidad de Terminología Médica, Real Academia Nacional de Medicina de España
The annotation task is being funded by Cátedra de Lingüística Computacional (Instituto de Ingeniería del Conocimiento)
The project favours continuity with future projects for improving the indexing of online repositories of biomedical articles, or developing lexicographic resources considering different varieties of Spanish.
Deliverables
-
Deliverable 1: Medical Lexicon for Spanish (MedLexSp), an unified Spanish lexicon of medical terms with linguistic and semantic information.
 Download a sample of the lexicon (including COVID-19-related terms)
Download a sample of the lexicon (including COVID-19-related terms) 
MedLexSp is freely distributed for research and educational purposes.
To get a copy, please, read and sign the usage license (in English or Spanish), and forward it to the email address below. If you use MedLexSp in your application or experiments, please, cite it as follows:
L. Campillos-Llanos (2019) First Steps towards Building a Medical Lexicon for Spanish with Linguistic and Semantic Information. Proc. of BioNLP 2019, August 1st, 2019, Florence, Italy.
@inproceedings{campillos-bionlp2019,
title = {First Steps towards Building a Medical Lexicon for Spanish with Linguistic and Semantic Information},
author = {Campillos-Llanos, Leonardo},
booktitle = {Proc. of BioNLP 2019},
location = {Florence, Italy},
year = {2019},
month = {August 1st}
} -
Deliverable 2: CT-EBM-SP corpus: a corpus of Clinical Trials for Evidence-Based-Medicine in Spanish.
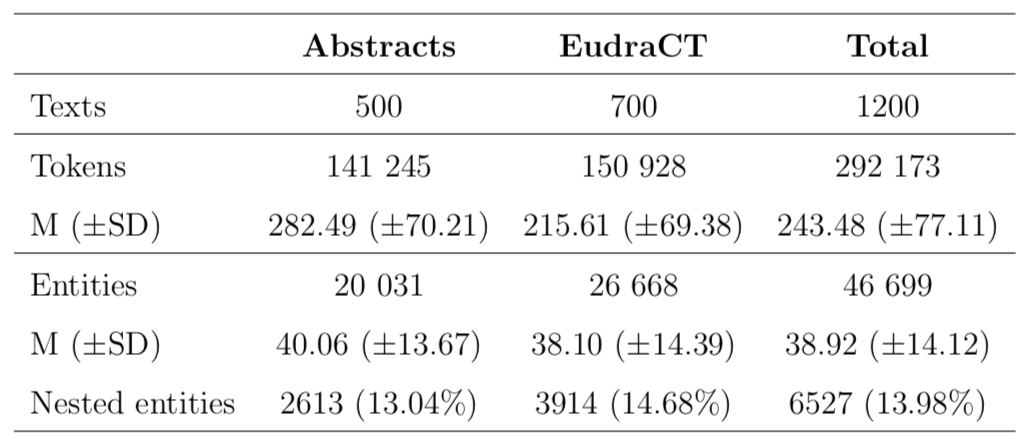
A collection of 1200 texts about clinical trials studies and clinical trials announcements:
- 500 abstracts from journals published under a Creative Commons license, e.g. available in PubMed or the Scientific Electronic Library Online (SciELO)
- 700 clinical trials announcements published in the European Clinical Trials Register and Repositorio Español de Estudios Clínicos

The corpus is freely distributed for research and educational purposes under a Creative Commons Non-Commercial Attribution (CC-BY-NC-A) License. 
Download
The corpus is annotated with entities from the Unified Medical Language System© (UMLS©)
Annotation guidelines are also available for download 
If you use this resource, please, cite it as follows:
Campillos-Llanos, Leonardo, Ana Valverde-Mateos, Adrián Capllonch-Carrión, Antonio Moreno-Sandoval (2021) A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine. BMC Medical Informatics and Decision Making. DOI: 10.1186/s12911-021-01395-z
@article{campillosetal-midm2021,
title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n and Moreno-Sandoval, Antonio},
journal = {BMC Medical Informatics and Decision Making},
year = {2021}
}The creators of the corpus are:
- Dr. Adrián Capllonch Carrión
- Dra. Ana Valverde Mateos
- Dr. Leonardo Campillos Llanos
- Dr. Antonio Moreno Sandoval
Table 1. Descriptive statistics of the corpus
-
Deliverable 3: Word-embeddings from the medical domain
Embeddings were trained with fastText and using the following parameters: skipgram model, window size = 10, dimensions = 100, minimum frequency = 1, number of negatives sampled = 10, learning rate = 1e-4
We used texts from the European Medicines Agency corpus (∼13.9M tokens) and articles from the Scientific Electronic Library Online (SciELO) repository (∼25M tokens)
Contact
Leonardo Campillos-Llanos, PhD, postdoctoral researcher.
Computational Linguistics Laboratory, Universidad Autónoma de Madrid
Interdisciplinary collaborations
-
Signed agreement



The National Royal Academy of Medicine of Spain (Real Academia Nacional de Medicina de España, RANME) will benefit of the results of the NLPMedTerm project.
The Lexicography team, who develops the Diccionario panhispánico de términos médicos (Pan-Hispanic Dictionary of Medical Terms), has provided terminology data for the project lexicon (WP1).
The NLPMedTerm project will provide UMLS data (Concept Unique Identifiers, Semantic Types and Groups) to be included in the Dictionary of medical terms developed by the RANME.
Publications
- L. Campillos-Llanos, Ana Valverde-Mateos, Adrián Capllonch-Carrión, Antonio Moreno-Sandoval (2021) A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine. BMC Medical Informatics and Decision Making. DOI: 10.1186/s12911-021-01395-z
- L. Campillos-Llanos (2019) First Steps towards Building a Medical Lexicon for Spanish with Linguistic and Semantic Information. Proc. of BioNLP 2019, August 1st, 2019, Florence, Italy.
Last update: January 2021.