Laboratorio de Lingüística Informática
Financiado por CICYT
Proyecto TIN2010-20644-C03-03
Enero 2011 a junio 2014
El proyecto tiene como objetivo el procesamiento de textos divulgativos sobre salud en idiomas como español, árabe y japonés. El resultado será una herramienta orientada al público en general para buscar información sobre enfermedades y medicamentos; y una herramienta específica para la traducción y la enseñanza de terminología en el dominio biomédico, mediante la extracción terminológica aplicada al corpus comparable de español, árabe y japonés.
La aportación del equipo del subproyecto de la UAM se han centrado en la compilación de los recursos lingüísticos (básicamente, los corpus médicos en varias lenguas) y en la elaboración del extractor automático de términos médicos en español, árabe y japonés.
Enlace a la página del proyecto (Facultad de Informática, Universidad Carlos III de Madrid)
Prototipo multilingüe de consulta de términos y extractor automático de términos
Estado actual
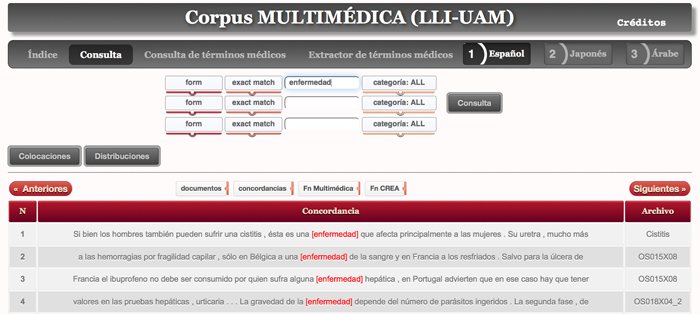
Se ha desarrollado una herramienta para la consulta del corpus y un extractor de términos médicos (pulse en la imagen de abajo para acceder a la aplicación):
 |
En el proyecto se han recopilado los siguientes bancos de datos:
Corpus español: se compone de tres recursos, cada uno reflejando un tipo de texto divulgativo en medicina:
Corpus japonés: está formado por resúmenes de revistas médicas de especialidades variadas. Incluye desde Medicina Oriental hasta Tocoginecología. El tamaño está dado en caracteres japoneses (que a su vez se dividen entre kanjis y kanas)
Corpus árabe: la mayor parte está formado por textos un portal médico de iniciativa jordana (Altibbi) que es equivalente portales americanos como Heathline. Este recurso proporciona artículos médicos y noticias divulgativas, pero con un control de calidad médico. Se complementa con las secciones de Salud y Medicina de tres periódicos de tres áreas geográficas y dialectales dentro del mundo árabe: Al-Awsat (Arabia Saudí); Youm7 (Egipto); y El Khabar (Argelia).
Tabla resumen de los corpus
| Kampo Medicine (Medicina Oriental en Japón) | ||
| Kansenshogaku Zasshi (Revista de enfermedades infecciosas) | ||
| Kanzo (Revista sobre enfermedades del hígado) | ||
| ORLTokyo (Otorrinolaringología japonesa) | ||
| Sanfujinka no shinpo (Avances en Tocoginecología) | ||
| Altibbi | ||
| Alawsat | ||
| Youm7 | ||
| ElKhabar | ||
| Harrison | ||
| OCU-Salud | ||
| Tu otro médico | ||
MORENO SANDOVAL, A., L. CAMPILLOS LLANOS, C. HERRERO ZORITA, J. M. GUIRAO MIRAS, A. GONZÁLEZ MARTÍNEZ, D. SAMY y E. TAKAMORI (2014) "An online tool for enhancing NLP of a biomedical corpus". 6º Congreso Internacional de Lingüística de Corpus (6th International Conference on Corpus Linguistics - CILC 2014). Las Palmas de Gran Canaria, 22-24 de mayo de 2014. 
MORENO SANDOVAL, A., y L. CAMPILLOS LLANOS (2013) "Design and annotation of MultiMedica - a multilingual text corpus of the biomedical domain". En Procedia - Social and Behavioral Sciences, 95, pp. 33 - 39 (Actas seleccionadas del 5º Congreso Internacional de Lingüística de Corpus 2013, Universidad de Alicante, España. 14 - 16 de marzo del 2013). Berlin: Elsevier. ISSN: 1877-0428.
2015
CAMPILLOS LLANOS. L. y H. UEDA (2015) "Frecuencia y dispersión léxicas en textos médicos divulgativos en español". En Ibérica, 29 (aceptado, publicable en 2015)
HERRERO-ZORITA, C., MOLINA, C. y MORENO-SANDOVAL, A. (2015) "Medical term formation in English and Japanese: A study of the suffixes –gram, -graph and –graphy". En Review of Cognitive Linguistics, 13 (1) (aceptado, publicable en 2015)
2014
HERRERO ZORITA, C., L. CAMPILLOS LLANOS, y A. MORENO SANDOVAL (2014) "Collecting and POS-tagging a lexical resource of Japanese biomedical terms from a corpus". Procesamiento del Lenguaje Natural, 52, pp. 29-36. ISSN: 1989-7553.
2013
CAMPILLOS LLANOS, L., MORENO SANDOVAL, A., y J. M. GUIRAO (2013) "An automatic term extractor for biomedical terms in Spanish". En Proceedings of the 5th International Symposium on Languages in Biology and Medicine (LBM 2013). 12-13 de diciembre de 2013. Tokyo, Japón . Premio al mejor póster del congreso.
HERRERO ZORITA, C., A. MORENO SANDOVAL, y L. CAMPILLOS LLANOS (2013) "Technology and Terminology. The Case of Japanese Medical Terms". Congreso Internacional Via Japan: Japan-Imprinted Discourses. Universidad Autónoma de Madrid. 24 de octubre de 2013
HERRERO ZORITA, C. (2013) "An initial approach on medical term formation in Japanese through the usage of corpora". En Andrew Hardie, y Robbie Love (eds.) Proceedings of the 7th Corpus Linguistics Conference 2013, pp. 339-341. Universidad de Lancaster (Reino Unido). 23 - 26 de julio del 2013. Lancaster: UCREL.
LANA-SERRANO, S., D. SÁNCHEZ-CISNEROS, L. CAMPILLOS LLANOS, e I. SEGURA-BéDMAR (2013) "Recognizing Chemical Compounds and Drugs: a Rule-Based Approach Using Semantic Information". En M. Krallinger, F. Leitner, O. Rabal, M. Vázquez, J. Oyarzábal, y A. Valencia (eds.) Proceedings of the Fourth BioCreative Challenge Evaluation Workshop vol. 2, pp. 121-128. Washington, DC, EE.UU. 8 de octubre del 2013. ISBN: 978-84-933255-8-9.
MORENO SANDOVAL, A., L. CAMPILLOS LLANOS, A. GONZÁLEZ MARTÍNEZ, y J. M. GUIRAO (2013) "An affix-based method for automatic term recognition from a medical corpus of Spanish". En Andrew Hardie, y Robbie Love (eds.) Proceedings of the 7th Corpus Linguistics Conference 2013, pp. 214-217. Universidad de Lancaster (Reino Unido). 23 - 26 de julio del 2013. Lancaster: UCREL.
SÁNCHEZ-CISNEROS, D., S. LANA-SERRANO, I. SEGURA-BÉDMAR, L. CAMPILLOS LLANOS, y P. MARTÍNEZ FERNÁNDEZ (2013) "A web prototype for detecting chemical compounds and drugs". En Adrian Paschke, Albert Burger, Paolo Romano, M. Scott Marshall, Andrea Splendiani (eds.) Proceedings of the 6th International Workshop on Semantic Web Applications and tools for life sciences (SWAT4LS), 10 de diciembre de 2013. Edimburgo, Reino Unido. ISSN: 1613-0073.
2012
LANA-SERRANO, S., D. SÁNCHEZ-CISNEROS, P. MARTÍNEZ FERNÁNDEZ, A. MORENO SANDOVAL, y L. CAMPILLOS LLANOS (2012) "An Approach for Detecting Modality and Negation in Texts by Using Rule-based Techniques". CLEF (Online Working Notes/Labs/Workshop) 2012. Roma, Italia, Septiembre de 2012. ISSN: 2038-4963.
SAMY, D., A. MORENO SANDOVAL, C. BUENO-DÍAZ, M. GARROTE-SALAZAR, y J. M. GUIRAO (2012) "Medical Term Extraction in an Arabic Medical Corpus". En N. Calzolari, K. Choukri, T. Declerck, M. Uğur Doğan, B. Maegaard, J. Mariani, J. Odijk y S. Piperidis (eds.) (2012) Proceedings of the 8th Language Resources and Evaluation Conference 2012. 23-25 May 2012. Istanbul, Turkey. ISBN 978-2-9517408-7-7.
SÁNCHEZ-CISNEROS, D., S. LANA-SERRANO, A. MORENO SANDOVAL, L. CAMPILLOS LLANOS, P. MARTÍNEZ FERNÁNDEZ, e I. SEGURA-BEDMAR (2012) "Prototipo de buscador de información médica en corpus multilingües y extractor de información sobre fármacos". Congreso de la Sociedad Española para el Procesamiento del Lenguaje Natural (SEPLN 2012). Publicado en Procesamiento del Lenguaje Natural, nº 49, septiembre de 2012, pp. 209-212. ISSN 1135-5948.
